
ポイント
- 国家統計である産業連関表は、これまで様々な形でサプライチェーンの脆弱性分析に利用されてきた。しかしこのデータは、分析単位が「産業」あるいは「製品」であり、企業(エンティティ)に関する情報を含んでいない。
- 一方、サプライチェーンの地政学的リスクを考えるには、「何(=どの製品)を取引しているか」だけでなく、「誰(=どの企業)と取引しているか」という視点も不可欠である。
- そこで筆者らは、企業単位での脆弱性指標を考案した。これを、エンティティリストや企業の支配関係情報と照らし合わせることで、特定企業に対するサプライチェーンの依存度を定量的に把握することができる。
「モノ」の規制と「主体」の規制
サプライチェーンの脆弱性を分析する試みは、従来、もっぱら産業連関表を用いる方法が主流となっていた。産業連関表とは、生産活動における財やサービスの取引関係について、経済の全体像を示した見取り図である。「どの産業が、どの産業に、どれだけ財やサービスを供給しているか」を金額ベースで整理しているので、産業間のつながりを俯瞰することができる。近年の研究事例としては、OECD(経済協力開発機構)の国際産業連関表を用いて、サプライチェーンの地理的集中リスクを分析した研究がある。
産業連関表の国際版である国際産業連関表は、その利便性ゆえ、グローバル・サプライチェーンの分析にも広く活用されてきた。しかし、それを経済安全保障の問題に全面的に適用するには一つ大きな制約がある。それは、分析単位が「産業」あるいは「製品」であり、企業(エンティティ)の情報が含まれていないという点である。
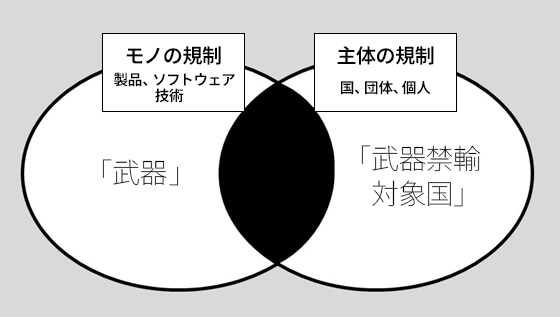
一般的に輸出規制は、「モノ(製品、ソフトウェア、技術)」と「主体(国、団体、個人)」という二つの軸から検討される。たとえば図1のように、武器輸出については、武器というカテゴリーに属する製品のリストと、武器禁輸対象国というカテゴリーに属する国のリストを照らし合わせ、その両方が重なった部分について輸出が制限される。すなわち、輸出規制は「モノ」と「主体」の掛け算で行われる(厳密には「用途」という第三の軸もある)。
すると、企業のサプライチェーン・リスクを考える際には、「何(=どの製品)を取引しているか」だけでなく、「誰(=どの企業)と取引しているか」という視点も不可欠となる。しかし、現行の国際産業連関表は企業に関する情報を含んでおらず、たとえば、取引相手が米国商務省のエンティティ・リスト(取引規制対象のリスト)に指定されたときのインパクトを把握することはできない。「モノ」の経済安全保障については分析可能だが、「主体=企業」については別のアプローチが必要だ。
企業のグローバル・ネットワーク・データ
企業の取引データを用いたサプライチェーン分析は、東日本大震災を契機に急速な発展を遂げた。災害の影響分析では、直接的に被災した企業を特定し、その被害の程度を外生値として分析モデルに与える必要がある。ところが、従来の災害分析で用いられてきた産業連関表は、あくまで産業と産業のつながり具合を示したデータにすぎず、企業レベルの情報、ことに被災企業とそれ以外の企業を仕分けるための情報を含んでいない。これが、災害分析において企業間ネットワーク・データの開発が促された大きな理由である。
以降、企業情報を用いたサプライチェーンのリスク分析は増えているものの、現時点では(前述の災害分析のように)もっぱら日本や米国など単一の国を対象とした研究に限られている。これは、ひとえにデータの制約によるところが大きい。
一方、サプライチェーンの地政学的リスクについては、主に国家間の対立から生じるものであり、その分析にあたってはグローバルな企業ネットワークのデータが不可欠である。
こうしたなか、昨今、学術的にも高い関心を集めているのが、FactSet Research Systems社が提供するデータベースである。同社は、金融データ、分析ツール、AIソリューションなどを提供する民間企業である。先述の災害分析で利用された企業データと比べると、もともとグローバル規模での企業分析を目的とする同社のデータベースは、その国際的な企業カバレッジの広さにおいて群を抜いている(表1)。現時点で、全世界617,245社について約234万件の取引関係を収録。データは毎年全面的に更新されており、また、企業の吸収合併などの情報も都度反映されるなど、即時性も備えている。
このデータは、各企業について以下の4つの関係軸に基づいて構成されている。
- (1)財・サービスの仕入先(「サプライヤー」)
- (2)製品の販売先(「カスタマー」)
- (3)ジョイントベンチャー・共同研究などの「パートナー」
- (4)「競合他社」。
また、これら関係性を定めるキーワードも併記されている(例 IBM:サプライヤー、マイクロソフト:カスタマー、キーワード:Xbox CPUsの供給)。
FactSetのデータベースは、上場企業が公表した情報をもとに作成されている。有価証券報告書(SEC Form 10-Kなど)、決算報告書、投資家向け情報、企業ウェブサイト、プレスリリースなど、情報源は極めて多岐にわたる。そして、各情報源から企業関係を示唆するキーワードを抽出し、それらを組み合わせることで、上記4軸の関係性が各企業に割り振られている。
さらに、各企業の個別情報を突き合わせることで、取引関係の片方で欠落している情報を、他方の情報によって補完する処理も行われている。たとえば、ウォールマート社が自ら公表したサプライヤーは11社のみであったが、この補完処理の結果、同社のサプライヤーとして415社が新たに特定された(2016年11月時点)。また、この手法により、非上場企業についても、上場企業が公開情報で取引関係を示していれば、その関係性を把握することが可能となる。
表1 掲載企業数 上位10か国・地域(2025年7月版)
| 米国 | 185,798 | カナダ | 21,277 |
|---|---|---|---|
| 中国 | 77,365 | インド | 20,725 |
| イギリス | 26,692 | イタリア | 19,048 |
| ドイツ | 24,112 | 韓国 | 15,426 |
| 日本 | 21,813 | 香港 | 13,423 |
出所:FactSetデータベースより計算。
サプライチェーンのリスク・エクスポージャー・マッピング(REM)
ただし、このデータベースだけでサプライチェーンの脆弱性を測ることは難しい。なぜなら、企業間の依存関係を示す取引量の情報がほとんど含まれていないからである。たとえば、企業Xと企業Yの間に取引があり、それぞれがサプライヤーとカスタマーのどちらであるかは示されているが、その関係の重要度までは知ることができない。
この問題に対し、現在、企業間取引ネットワークと生産統計の情報を組み合わせた分析が進められている。なかでも筆者らが共同開発を続ける「リスク・エクスポージャー・マッピング(REM)」は、サプライチェーンの地政学的リスクに特化した分析ツールである。
たとえば昨今、自動車業界を震撼させた、ネクスペリアによる供給停止問題を考えよう。オランダの半導体メーカーである同社は、2019年に中国の電子機器大手、ウィングテック(聞泰科技)に買収され、その資本傘下に入った。ネクスペリアは主に車載用の半導体を製造しており、中国広東省に最大級の工場を擁している。欧米自動車メーカーへの主要な半導体サプライヤーであるが、今般、中国政府の指示により、中国からの製品輸出を一時停止または許可制に変更する方向に動いた。
問題の発端は米中対立にある。今年9月末に米国商務省がエンティティリストの適用対象を拡大し、リスト掲載企業が持株比率50%以上で資本参加する企業についても取引制限が課される形となった。その結果、親会社のウィングテックがリスト掲載企業であったネクスペリアも、同様に米国輸出管理規則(EAR)による規制対象となったのである。
この流れのなか、9月末、オランダ政府は「国家安全保障上の懸念」からネクスペリアの経営権を強制的に接収した。今回の中国による輸出制限は、このこと対する報復行為と見られている。
結局、11月に入り、輸出制限措置は条件付きで緩和されることとなったが、同社製品への依存が大きい自動車業界には少なからぬ混乱を巻き起こした。
図2はREMデータを用い、米・日・独・韓の主要な自動車メーカーの、ネクスペリアに対する製品(半導体)調達依存度を比較したものである。メディアでもしばしばその動向が報じられている独フォルクスワーゲンの依存度が最も高い。
また、図3は依存度を地域別に見たものである(ここでは、たとえばトヨタやホンダなど日系企業であっても、その事業所が米国にあれば、米国自動車業界の依存度として計算されている)。米国の依存度が突出しているが、これも企業ごとに分け入ると、フォルクスワーゲンの米国拠点が数値を引き上げていることがデータで確認されている。
自動車という最終製品を考えた場合、エンジンや電子制御ユニット(ECU)など、1次サプライヤーから直接的に仕入れる部品については、完成車メーカーの部品構成表(Bill of Materials: BOM)を参照することで、それらへの調達依存度を相応に計ることが可能である。しかし、半導体製品など取引階層が何段階も上流に位置する部材の供給については、REMのようなネットワーク解析による構造的アプローチが有効だ。
総じて、REMでは全世界約62万社を対象に企業間依存度を計算し、それをエンティティリストや企業の所有関係と照らし合わせることで、各サプライチェーンが抱えるリスクを定量的に把握することができる。その利点としては、①FactSetデータがカバーするほぼすべての企業を分析対象とできること(包括性)、②FactSetのデータ更新に合わせて再計算が可能なこと(即時性)、そして③企業の支配関係という側面も参照できること(多元性)、といったことが挙げられる。
経済安全保障という特殊な問題群に対しても、極めて実用性が高いツールであると評価できよう。
図2 ネクスペリアに対する部品調達依存度
出所:筆者作成。注:縦軸は11社の平均値をベンチマークとした指数。
図3 ネクスペリアに対する部品調達依存度(国/地域別)
出所:筆者作成。注:横軸には、データに含まれる自動車メーカーの事業所数が10社以上の国・地域(中国を除く)を列記した。カッコ内は事業所数。縦軸は、これら17か国/地域の平均値をベンチマークとした指数。
今後の展開:生成AIを用いたデータ構築
オープンソースによるデータ作成では様々な情報源が参照されるが、それらは必ずしも有価証券報告書のように書式が統一されたものばかりではない。また、有価証券報告書でさえ、生産活動の業種ラベルが統一されていないなど、手作業での情報マッチングが極めて困難な状況となっている。
こうした状況のなか、現在、大きな期待が寄せられているのが、生成AIを利用した情報収集・データ作成である。インターネット上に散在する様々な関連情報を網羅的に取り込み、仕分けし、整合化するという作業を、大規模言語モデルによって統一的に行うのである。
現段階では、製品レベルでの技術連関構造(投入・産出)を抽出したデータが開発されているが、企業レベルでの生産ネットワークについてはなかなか応用が進んでいない。これには、オープンソースの情報からは事業所単位の活動を特定できないこと、また、個票単位の通関データは様々な国でアクセスが制限されていることなどが理由として挙げられる。
しかし今後、利用可能なデータ領域が広がるにつれ、その規模や異質性を踏まえたデータ構築・解析の手法として、生成AIの有効活用はますます重要となる。サプライチェーンの脆弱性分析においても、今後の展開を注視したい。
(c)Alamy Stock Photo/amanaimages
